مدل سازی آرایه فتوولتاییک با شبکه عصبی:
مدل های مبتنی بر شبکه عصبی مصنوعی (ANN) راهکاری برای حل مشکل شرایط آب و هوایی متغیر هستند که رابطه غیرخطی بین متغیرهای ورودی و خروجی سیستم پیچیده را توصیف می کنند.

توانایی خودیادگیری شبکه های عصبی، مزیت اصلی این مدل ها محسوب می شود. بنابراین، این مدل ها حین عملکرد نامعین، مانند توان خروجی آرایه سیستم، دقیق هستند.
شبکه عصبی مصنوعی، مجموعه ای از تکنیک های پردازش اطلاعات با الهام از رویکرد اطلاعات پردازش سیستم عصبی بیولوژیکی است. یک ANN از واحدهای جزئی موازی به نام نرون تشکیل شده است.
نرون ها به وسیله شمار زیادی از پیوندهای وزنی به هم وصل می شوند که امکان انتقال سیگنال یا اطلاعات را دارند.
یک نرون، ورودی ها را از طریق اتصالات ورودی خود دریافت و ورودی ها و خروجی ها را ترکیب می کند. مفهوم اصلی شبکه های عصبی ساختار سیستم پردازش اطلاعات، مشابه تکنیک تفکر انسان است. شبکه عصبی می تواند رابطه بین متغیرهای ورودی و خروجی را با مطالعه داده های ثبت شده قبلی یاد بگیرد.
مزیت اصلی ANN این است که با استفاده از آن می توان برای مسائل پیچیده مربوط به فناوری های معمول که راه حل الگوریتمی ندارند یا برای حل نیازمند یک الگوریتم پیچیده تر هستند، راه حل مناسبی ارائه کرد.
برخی از شبکه های عصبی مختلف، عبارتند از: «شبکه های عصبی تابع پایه شعاعی» ( Radial Basis Fnction Networks) یا RBF، «شبکه های پیوند تابعی» (Functional Link Networks)، «شبکه های عصبی رگرسیون عمومی» (General Regression Neural Networks) یا GRNN، «شبکه های کوهونن» (Kohonen Networks)، «شبکه های رو به جلوی آبشاری» (Cascade Forward Neural Network) یا CFNN، «شبکه های عصبی پیش خور» (Feedforward Neural Network) یا FFNN، «شبکه های گرام-شارلی» ( Gram-Charlier Networks)، «کوانتیزاسیون بردار یادگیری» (Learning Vector Quantization)، «شبکه های هب» (Hebb Networks)، «شبکه های آدلاین» (Adaline Networks)، «شبکه های غیرمشارکتی» ( Heteroassociative Networks)، «شبکه های بازگشتی» (Recurrent Networks) و «شبکه های ترکیبی» (Hybrid networks) هستند.
در این آموزش، شبکه های FFNN، GRNN و CFNN را برای مدل سازی جریان خروجی آرایه فتوولتاییک انتخاب می کنیم.
برای انتخاب بهترین مدل جهت این کار، شبکه های عصبی مختلف مانند CFNN و FFNN مقایسه شده اند. این مدل ها با استفاده از متلب تشکیل شده، آموزش دیده و اعتبارسنجی می شوند.
GRNN یک شبکه مبتنی بر احتمالات است. این شبکه وقتی متغیر هدف قطعی است طبقه بندی انجام می دهد، در حالی که وقتی متغیر هدف پیوسته باشد رگرسیون انجام می دهد.
GRNN ها شامل لایه های ورودی، الگو، جمع کننده و خروجی هستند. شکل 1 نمودار کلی GRNN را نشان می دهد.
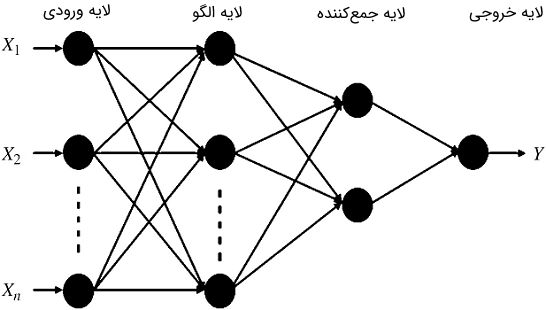
شکل 1: نمودار شماتیکی GRNN
DFNN یک شبکه «خودسازمانده» و به نوعی شبیه FFNN است. هر دو شبکه مذکور از الگوریتم پس انتشار (BP) برای به روزرسانی وزن ها استفاده می کنند. شکل 2 نمودار شماتیک کلی CFNN را نشان می دهد.
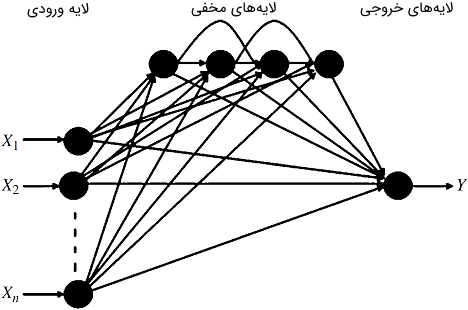
شکل 2: نمودار شماتیکی CFNN
از سوی دیگر، شکل3 نمودار شماتیک FFNN را نشان می دهد. این شبکه شامل لایه های ورودی، مخفی و خروجی است. پیش خور بدین معنی است که مقادیر فقط از لایه ورودی به لایه مخفی و سپس به لایه های خروجی حرکت می کنند.
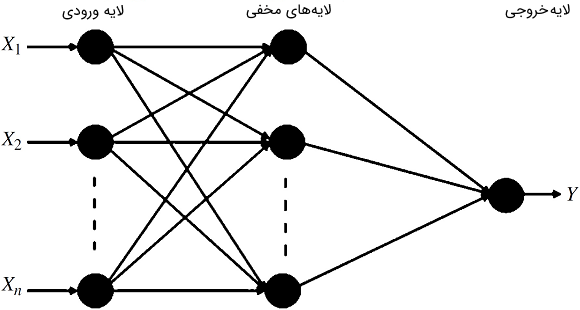
شکل3: نمودار شماتیکی FFNN
بدون آموزش دادن و تخمین خطای تعمیم، هیچ قاعده مستقیمی برای یافتن تعداد بهینه نرون های مخفی وجود ندارد. با این حال، اگر تعداد نرون های مخفی کم باشد، ممکن است کم برازش رخ دهد که سبب خطای آموزش و خطای تعمیم بالا خواهد شد.
هنگامی که تعداد زیادی نرون در لایه مخفی اعمال شود، بیش برازش و واریانس بالا رخ می دهد. معمولاً تعداد گره های مخفی را می توان با برخی قوانین سرانگشتی به دست آورد. برای مثال، تعداد نرون های لایه مخفی باید عددی بین اندازه لایه ورودی و اندازه لایه خروجی باشد.
برخی نیز پیشنهاد کرده اند که تعداد نرون های مخفی نباید بیش از دو برابر تعداد ورودی ها باشد. در جایی دیگر توصیه شده که تعداد گره های مخفی دو سوم یا 70 تا 90 درصد تعداد گره های ورودی باشد.
بر اساس پیشنهادهای فوق، تعداد نرون های لایه مخفی مدل های FFNN و CFNN برابر با دو گره مخفی در نظر گرفته شده اند.
برای ارزیابی مدل پیشنهادی، از سه خطای آماری استفاده شده است که عبارت اند از: «درصد میانگین قدر مطلق خطا» (Mean Absolute Percentage Error) یا MAPE، «خطای انحراف میانگین» (Mean Bias Error) یا MBE و «خطای جذر میانگین مربعات» (Root Mean Square Error) یا RMSE.
دقت کلی یک شبکه عصبی را می توان با MAPE بررسی کرد. MAPE به صورت زیر تعریف می شود:

که در آن، M داده های اندازه گیری شده و P داده های پیش بینی شده هستند.
از سوی دیگر، شاخص انحراف میانگین مقادیر پیش بینی شده از داده های اندازه گیری شده را می توان با MBE بیان کرد. مقدار MBE مثبت نشان دهنده تخمین بیش از حد است. اطلاعات عملکرد طولانی مدت مدل شبکه عصبی نیز با MBE ارزیابی می شود. MBE را می توان به صورت زیر محاسبه کرد:

که در آن، M داده های اندازه گیری شده و P داده های پیش بینی شده هستند.
شاخص خطای آماری که در این آموزش استفاده می شود RMSE است. اطلاعات عملکرد کوتاه مدت مدل را می توان با RMSE ارزیابی کرد.
این، نشان دهنده اندازه گیری تغییرات داده های پیش بینی شده حول داده های اندازه گیری شده است. همچنین RMSE نشان دهنده بازدهی مدل تشکیل شده در پیش بینی مقادیر بعدی است. یک RMSE مثبت و بزرگ، انحراف بزرگ در داده های پیش بینی شده از داده های اندازه گیری شده را نشان می دهد.
RMSE را می توان با فرمول زیر محاسبه کرد:












